MySQL- 基础语法
MySQL- 基础语法
- LAMP 最流行的开源服务器端技术之一,适合中小型站点,web应用,linux+Apache+MySQL+php
- mysql中表头的结构与Excel的表头结构 相反
- Excel表头是朝上横向排列,mysql里是向左纵向排列
- 所有语句必须英文分号(;)结尾,一条语句可以编写在多行中
- 单词不区分大小写,编写关键字时使用大写形式,其他小写
客户端与服务器端建立连接
- 数据库分为服务器端与客户端,如需使用数据库,客户端必须与服务器端建立连接
- 服务器端(相当于银行总部)
- phpstudy、XAMPP等等调试环境的集成软件包
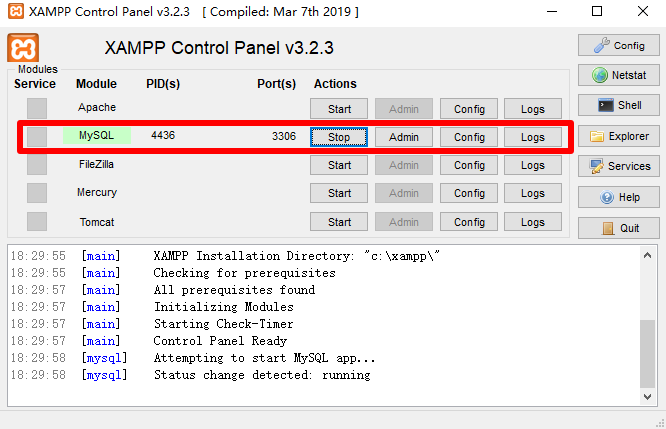
- 客户端(相当于ATM机)
- CMD面板等等类似终端
- 客户端与服务器端建立连接
完整语法
第一项为软件名称,第二项为IP地址,一般都是本机地址(也可用localhost代替),不用修改。第三项为端口,默认不用修改。第四项为登录用户名,root为最高管理员权限。第五项为用户登录密码,root没有密码,故不用填写。
mysql.exe -h127.0.0.1 -P3306 -uroot -p简写语法
2,3,5项一般情况下都是默认属性,简写模式下可以省略
mysql -uroot连接并提交脚本
需先退出終端后操作,脚本格式后缀一般都为.sql,脚本路径也可直接拖拽至终端,会自动生成路径
mysql -uroot<脚本路径
注释
# 此为单行注释
/*
此为多行注释
此为多行注释
此为多行注释
*/
常用MySQL管理命令
- MySQL指令分为管理指令与操作指令
- 命令行链接mysql后,可以发起俩种操作指令
1.MySQL管理命令
- 管理MySQL系统的指令,专用于MySQL服务器
- quit; 退出服务器的连接
- 如遇意外情况导致无法退出时,可直接按ctrl+c快捷键强制退出
- show databases; 显示当前数据库服务器下所有的数据库
- use 数据库名; 进入指定的数据库
- show tables; 查询数据库里有哪些表
- desc 表名; 描述表里有哪些列(列也叫字段)
2.SQL操作命令
- 操作数据库中数据的指令,也可适用于其他的数据库
- SQL语句可分为以下四大类
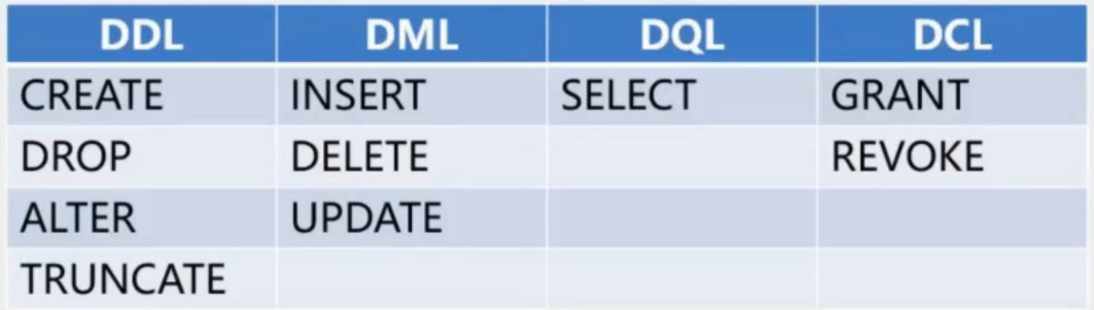
2-1. DDL语句(定义数据的结构)
DROP DATABASE 丢弃数据库
- sql脚本建库时,需要在脚本顶部写丢弃数据库的命令,先丢弃数据库,否则无法在终端重复提交。目的是为了防止重复提交,重复创建,重复执行导致的报错。原理是执行脚本时,I F先判断是否有同名的库,如果有,删掉已有库后创建,没有就直接创建
DROP DATABASE IF EXISTS 数据库名;
CREATE DATABASE 创建数据库
- 创建一个新的数据库
CREATE DATABASE 数据库名;
CREATE TABLE 创建表
- 创建数据库后,按结构必须要创建一个表及该表下有哪些列名(字段),列类型属性。
CREATE TABLE 表名(
列名称 列类型属性,
......,
......,
.....
);
ALTER 修改数据
- 修改数据,暂时未用到,后期做详解
TRUNCATE 清空数据
- 清空数据,暂时未用到,后期做详解
2-2. DML语句(操作数据,增删改)
INSERT 插入数据
- 插入一条新的数据(需要在创建表名的基础上)
<-- 插入一条完整数据--!>
INSERT INTO 表名 VALUES(
列1的值,
列2的值,......
);
<-- 部分插入:指定字段插入数据--!>
INSERT INTO 表名(列名称) VALUES(“值”)
DELETE 删除数据
- 删除表的数据,加上条件(WHERE 条件)的话,则删除的是符合条件的数据。如果不加条件(WHERE 条件)的话,则默认是删除所有的数据
DELETE FORM 表名 WHERE s;
UPDATE 修改数据
- 修改表的数据,SET是连接该条数据,加上条件(WHERE 条件)的话,修改的是符合特定条件的属性值,不加条件的话则是所有属性值相同的都会被修改。
UPDATE 表名 SET name='tom',score='93' WHERE s;
2-3. DQL语句(查询数据)
SELECT 查询数据
- 查询数据,*号意指所有 FROM是指从哪开始
SELECT * FROM 表名;
2-4. DCL语句(控制用户的权限)
3.MySQL建库及数据实例:
- 需求:创建学子数据库,并创建相应数据,增删改查数据。
- 丢弃数据库xz
- 创建数据库
- 进入创建的数据库
- 创建保存用户数据的表
- 插入数据
- 删除数据
- 修改数据
- 查询数据
# 设置客户端与服务器端的编码
SET NAMES UTF8
# 丢弃已有数据库xz
DROP DATABASE IF EXISTS xz;
# 创建数据库xz,并设置数据库编码
CREATE DATABASE xz CHARSET=UTF8;
# 进入数据库xz
USE xz;
# 创建数据表
CREATE TABLE user(
uid INT,
uname VARCHAR(16),
email VARCHAR(32),
phone VARCHAR(11),
headpic VARCHAR(64),
userName VARCHAR(8),
sex VARCHAR(1) # f为女性,m为男性
);
# 插入数据
INSERT INTO user VALUES(
'1',
'TOMANDJERRY',
'123456@qq.com',
'12344423221',
'123.jpg',
'tom',
'm'
);
INSERT INTO user VALUES(
'2',
'TOMANDJERRY',
'123456@qq.com',
'12344423221',
'123.jpg',
'tom',
'm'
);
INSERT INTO user VALUES(
'3',
'TOMANDJERRY',
'123456@qq.com',
'12344423221',
'123.jpg',
'tom',
'm'
);
INSERT INTO user VALUES(
'4',
'TOMANDJERRY',
'123456@qq.com',
'12344423221',
'123.jpg',
'tom',
'm'
);
INSERT INTO user VALUES(
5,
'TOMANDJERRY',
'123456@qq.com',
'12344423221',
'123.jpg',
'tom',
'm'
);
# 删除数据
DELETE FROM user WHERE u;
# 修改数据
UPDATE user SET userName='locy' WHERE u;
解决MySQL中文乱码
- mysqlm默认使用Latin-1编码,不兼容中文,所以出现乱码
- 解决方法为:
脚本文件编码另存为UTF8
客户端连接服务器端的编码为UTF8
- sql脚本中顶部添加命令
SET NAMES UTF8
- 服务器端创建数据库使用的编码为UTF8
- 脚本中创建数据库命令中加 CHARSET=UTF8
CREATE DATABASE 库名 CHARSET=UTF8;
列类型
- 用于限定在指定列上可以保存的数据的格式
存储单位详解
1,单位换算
- 计算机存储数据采用二进制存储,存储单位为字节
- 1字节= 8位(二进制位)
- +111 1111 最大(相当于十进制的 0 ~ 127)
- -111 1111 最小 (相当于十进制的 -1 ~ -128)
2,进制转换
编程中常用十进制、八进制、十六进制等作为表示方法
例1:十进制转二进制方法
整数除以2直至商为0后取余数,余数倒序重拍
如图所示:蓝框为商,绿框为余数
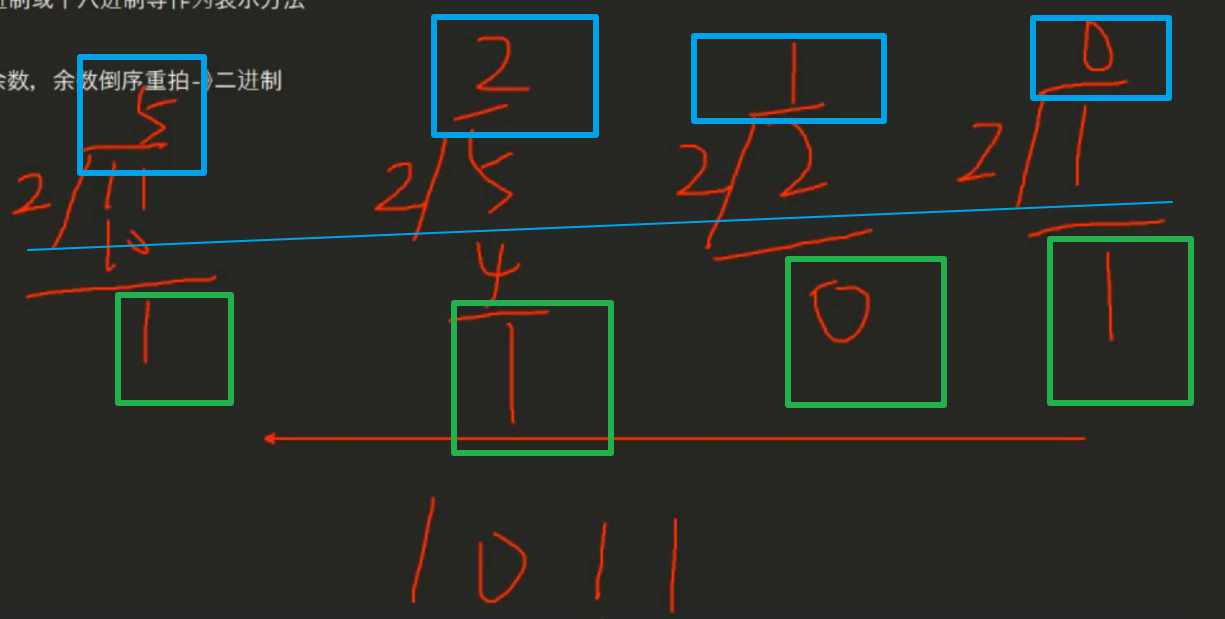
例2:二进制转十进制方法
从右向左依次代表2的相应次幂(次幂排序是0,1,2,3,4...也是从右向左),每一位数字(二进制上的位)乘以当前位上2的相应次幂后累加,次幂计算公式为:2的3次幂=2* 2* 2
如图所示:图1倒序排列后 * 同样倒序排列后的2的相应次幂,然后每一位上计算的结果累加等于图3
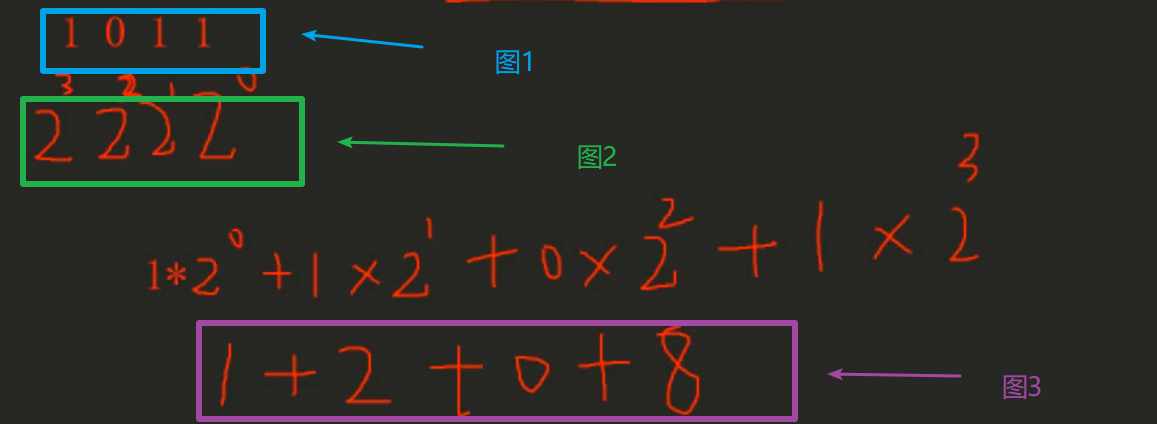
数值类型
- 注意:范围代指十进制的范围,TINYINT,SMALLINT,INT所指范围需牢记
- FLOAT,DOUBLE存储的过程中需要牺牲最后几位来做10的N次方计算,所以精度会受到影响,多用于贸易差,天文运算等大型运算,范围要比BIGINT大的很多,日常使用很少。
- (M,D)M表示有效位数,D表示小数点后面允许的有效位数
1.TINYINT
- 微整型,占1个字节,范围为-128~127
2.SMALLINT
- 小整型,占2个字节,范围-32768~32767
3.INT
- 整型,占4个字节,范围-2147483648~2147483647
4.BIGINT
- 大整型,占8个字节,范围很大
5.FLOAT(M,D)
- 单精度浮点型,占用4个字节
6.DOUBLE(M,D)
- 双精度浮点型,占用8个字节
7.DECIMAL(M,D)
- 严格定点小数,用于保存精确小数,
8.BOOL
- 布尔型,也称是否类型,不能加引号,只有俩个值,分别是TRUE/FALSE,真正存储时会自动转为TINYINT,TRUE/FALSE自动转为1/0,所以也可以直接插入数字1/0
字符串类型
- 注意:字符串必须要加引号
1.CHAR(M)
- char指固定字符数量,长度最大为255个字符,如指定CHAR(5)存入了2个字符,其余三个字符系统会自动补全,会形成空间浪费,换来的是运行效率的提升
2.VARCHAR(M)
- varchar是长度可变的字符串,长度最大为65535个字符,如指定VARCHAR(5)存入了2个字符,后面剩余三个字符系统自动补全1个字符代替剩余未用的字符长度,不会形成空间浪费,但会影响运行效率
3.TEXT(M)
- text长度可变的字符串,长度最大为2的32次方,约等于4G个字符
日期时间类型
- 注意:为了解决不同的日期时间存储形式,可以存储为距离计算机元年毫秒数(1970-1-1 0:0:0),用BIGINT类型存储,配合JS写出所需的时间格式(具体待实例验证),日期、时间和日期时间类型默认加“”
1.DATE
- 日期类型,支持的范围是“1000-01-01”到“9999-12-31”
2.TIME
- 时间类型,支持的范围是“00:00:00”到“23:59:59”
3.DATETIME
- 日期时间类型,支持的范围为“1000-01-01 00:00:00”到“9999-12-31 23:59:59”
类型存储建议
- CHAR 存储固定长度的数据,身份证号码 手机号等操作速度相对快
- VARCHAR 存储变化长度的数据 文章标题 姓名 相对操作速度慢
- ID 编号 INT类型
- 年龄 TINYIN类型
- 价格等固定小数 DECIMAL类型
- 性别 BOOL类型
- 日期 项目中多用BIGINT
- 文章内容 VARCHAR类型
列约束
1.PRIMARY KEY(主键约束)
- 主键在一张表里是唯一的
- 主键的值是非空(NULL)的
- 一般给ID编号加主键,会默认从小到小排序,加快查询速度
- 主键自增:AUTO_INCREMENT(需要验证自增后的主键取值,及原理过程)
- 在主键约束后空格隔开加上AUTO_INCREMENT可以实现主键自增(可以直接给值为NULL),建议默认就加上
- 添加主键自增后,部分表会出现乱序,也是正常的,因为默认mysql查询数据时,会优先查询内存里最快的到最慢的进行排序,以增加查询效益
2.NOT NULL(非空约束)
- 限定指定列上的值不能为空(NULL)
3.UNIQUE(唯一约束)
- 限定指定列上的值不能出现重复值,但允许出现多个NULL(NULL≠任何值,俩个NULL也是≠不等的)
4.CHECK(检查约束)
- MySQL的初始InnoDB引擎默认不支持检查约束
- 因为容易频繁查询对数据库造成压力
- 一般在前端以JS方式进行约束
5.FOREIGN KEY(默认值约束)
- 默认值约束用来指定某列的默认值
- 创建表时添加默认值约束
- 语法:default 默认值
CREATE TABLE tempStudent(
sno INT PRIMARY KEY AUTO_INCREMENT,
sname VARBINARY(50),
sdept VARBINARY(50) NOT NULL,
sage INT NOT NULL DEFAULT 18, //默认值为18
CONSTRAINT uni_sname UNIQUE (sname)
);
2.修改表字段时添加默认值约束????? ALTER TABLE tempStudent MODIFY sage INT NOT NULL DEFAULT 18;
3.删除默认值约束(修改字段属性)????? ALTER TABLE tempStudent MODIFY sage INT NOT NULL ;
6.FOREIGN KEY(外键约束)
- 让俩个表里的指定数据产生联动,是否可以一对多> ?> ?> ?> ?> ?
- 外键约束是在插入数据中最后面填写
- 外键约束上的值必须要和另一个表格上的值一致,NULL除外
- 俩个表格里指定的列类型必须保持一致
- 外键约束取值必须要在另一个表上主键约束的值
FOREIGE KEY(当前表指定的列名称) REFERENCES 另一个表名(另一个表名里指定的列名称)
简单查询
1. 查询特定的列
- 示例:查询出所有员工的姓名和工资
SELECT 列名1,列名2 FORM 表名;
2. 查询所有的列
SELECT * FORM 表名;
3. 给列起别名
- 列名称后面写关键字AS(关键字AS可以省略,空格必须要加),然后空格加别名
SELECT 列名1 AS 别名1,列名1 AS 别名2 FROM 表名:
SELECT 列名1 别名1,列名2 别名2 FROM 表名;
4. 显示不同的记录
显示不同的记录,合并相同的项,去重处理
在列名的前面加上关键字DISTINCT
示例:查询出有哪些性别的员工
SELECT DISTINCT 列名 FROM 表名;
5. 查询时执行计算
查询并执行计算时,如需给计算结果起别名,但要主要别名要放在计算结果后
示例:查询出所有员工的的姓名及其年薪
SELECT ename,salary*12 s FROM 表名
//ename是姓名的列名称,salary是薪资的列名称,s是计算结果的别名
6. 查询结果集排序
在列名前(表名后)加ORDER BY关键字是表示从指定的列开始,然后在列名后加DESC(此处的DESC和之前的DESC不一样,此处代表降序关键字的简写)
ASC为升序关键字,DESC为降序关键字
查询结果集排序时,如果表名后不加排序关键字,则默认是升序,但必须要加ORDER BY
可以设置多个排序规则,指定多个列名
示例1:查询所有的部门,结果集按照部门编号进行降序或升序
SELECT * FROM 表名 ORDER BY 列名 DESC
//表示从指定表里指定列进行排序
- 示例2:查询所有员工,结果集按照工资的升序排列,如果相同,则按年龄升序排列
SELECT * FROM 表名 ORDER BY 列名1,列名2;
//表示从指定表里指定列名1进行升序排列,如果值相同则按照列名2进行升序排列
7. 条件查询
查询表里指定条件的列,字符需要加引号
示例1:
SELECT * FORM 表名 WHERE 列名=具体指定条件的值;
SELECT * FORM 表名 WHERE 列名="具体指定条件的值";
运算符有:
(大于)、<(小于)、>=(大于并等于)、<=(小于并等于)、=(等于)、!=(不等于)
示例2:查询出工资在5000以上的员工有哪些?
SELECT * FORM 表名 WHERE 列名>5000;查询非空条件时(查询NULL值),只能用关键字查询
IS NULL是条件为NULL的关键字,IS NOT NULL是条件除了NULL以外的关键字
示例3:查询出没有明确部门的员工有哪些或有明确部门的员工
SELECT * FROM 表名 WHERE 列名 IS NULL;
//查询没有明确部门的员工
SELECT * FROM 表名 WHERE 列名 IS NOT NULL;
//查询除了没有明确部门的员工,其它员工有哪些
AND关键字代表俩个条件同时成立下的连接,是代表并且的意思
BETWEEN AND关键字代表一个范围的连接
NOT BETWEEN AND关键字代表不在一个范围的连接
示例4:
SELECT * FORM 表名 WHERE 列名>=5000 AND 列名<7000;
//查询工资在5000(包含5000)并且小于7000(包含7000)的员工有哪些
SELECT * FROM 表名 WHERE 列名 BETWEEN 5000 AND 7000;
//查询工资在5000~7000范围内的员工有哪些
SELECT * FROM 表名 WHERE 列名 NOT BETWEEN 5000 AND 7000;
//查询工资不在5000~7000范围内的员工有哪些
OR关键字代表或者的意思
示例5:查询出工资在5000以下或7000以上的员工有哪些?
SELECT * FROM 表名 WHERE 列名<5000 OR 列名2>7000;IN关键字与OR类似,同样表示或的意思
IN关键字表示在这个条件之内,NOT IN表示不在这个条件之内
示例6:
SELECT * FORM 表名 WHERE 列名 IN(条件1,条件2);
//查询出在20号部门或在30号部门的员工有哪些?
SELECT * FORM 表名 WHERE 列名 NOT IN(条件1,条件2);
//查询出不在20号部门或在30号部门的员工有哪些?
8. 模糊条件查询
- LIKE关键字代表模糊条件
- % 占位符,匹配任意多个字符 >=0
- _ 占位符,匹配任意一个字符 =1
- 以上俩个占位符(匹配符)必须结合LIKE关键字使用
- 示例1:
SELECT * FROM 表名 WHERE 列名 LIKE "%e%"
//查询姓名中含有e的字符有哪些
SELECT * FROM 表名 WHERE 列名 LIKE "%e"
//查询姓名中以e结尾的字符有哪些
SELECT * FROM 表名 WHERE 列名 LIKE "%e_"
//查询姓名中倒数第二个字符是e的有哪些
9. 分页查询
- 每页数据是按照索引排序
- LIMIT为分页查询关键字,后面的数字第一个代表数据从索引几开始
- 第二个为每页数据的数量
- 计算方法为:(当前页码-1)* 每页数据量
- 已知条件必须确定
- 每页数据量
- 当前页码
SELECT *form 表名 LIMIT 索引 每页的数据量;
示例:需要查询第9页,每页显示5条数据,计算方法为: (9-1)* 5=40
SELECT *form 表名 LIMIT 40,5;分页查询综合语法:
SELECT * FORM 表名 [WHERE 条件] [排序方式] LIMIT 索引 每页的数据量
数据库建表分析
- 前期做足分析,制作模型图,按照模型图依次建表
- 边创建边关联(贴近开发实战) 2-1. 分析需要哪些表,单独创建每张表 2-2. 分析表之间的关联关系,构建外键 拓展语法: 关键字:alter table快速构建关联,需要再插入数据之前构建关联 alter table 表名(需要设置外键的表)add foreign key (需要设置外键关联的列名) references 关联的主表名(列名)
复杂查询
1. 分组查询(聚合查询)
- 分组查询和聚合查询不能使用 *
1-1. 聚合查询
- 聚合查询提供了5个聚合函数
- 不同的聚合函数可以相计算,运算符再放在中间
- 示例:
SELECT SUM(表名)/COUNT(表名) FORM 表名;
- count(列名) --列的个数
- 查询个数时,如果有NULL值,查询结果会不加NULL
- 建议查询有主键约束的列
SELECT COUNT(列名) FROM 表名
sum(列名) --列的总和
SELECT SUM(列名) FROM 表名AVG(列名) --列的平均值
SELECT AVG(列名) FROM 表名MAX(列名) --列的最大值
SELECT MAX(列名) FROM 表名MIN(列名) --列的最小值
SELECT MIN(列名) FROM 表名
1-2. 分组查询
- 分组查询关键字为 GROUP BY
- 分组查询中只能查询聚合查询和分组条件
- 示例:
SELECT 分组条件为具体列名, 聚合函数, FORM 表名 GROUP BY 对应前面的分组条件
//SELECT 后面的分组条件一定要和GROUP BY 后面的分组条件一致对应
2. 子查询
YEAR()函数是查询年份的函数
AND关键字是并且的意思
又称为嵌套查询,顺序从 ( ) 里向外执行
语法:
SELECT * FORM 表名 WHERE 列名 >( SELECT 列名 FROM 表名 WHERE 列名="列值")
//从左到右依次表示查询条件大于( )内的条件
- 示例1:查询出和tom同一年出生且不包含tom的员工有哪些?
- 思路步骤为:
- 查询出tom的出生年份
SELECT YEAR(birthday) FROM 表名 WHERE ename="tom";
//查询表名里的 birthday列并赋值给专门查年份的YEAR()函数 条件为enmae="tom"
- 查询出和tom同一年的员工,且不包含tom
SELECT * FROM 表名 WHERE YEAR(birthday)=(SELECT YEAR(birthday) FROM 表名 WHERE ename="tom";) AND ename!="tom";
//查询指定YEAR()函数内的条件相等的员工有哪些,并且名字不包含不等于tom
3. 多表查询
避免笛卡尔积错误,笛卡尔积错误就是将A表的每一条记录与B表的每一条记录强行拼在一起,如果A有N条记录,B有M条记录,笛卡尔积产生的结果就会是n*m条记录
多表查询时使用INNER JOIN 和ON关键字联合查询数据,> 多表之间需存在关联关系
mysql旧版本不能使用INNER JOIN 和ON关键字进行联合查询
mysql旧版本多表查询语法容易出现笛卡尔积错误,解决办法为:添加查询条件,但是并不能完全解决问题
示例1:
SELECT 表1的列1, 表2的列1 FROM 表1, 表2;
//查询结果容易出现笛卡尔积错误
SELECT 表1的列1, 表2的列1 FROM 表1, 表2 WHERE 表1的条件=表2的条件;
//无法查询出没有值的列,也无法查询出存在NULL值的列
新增的多表查询
- ON关键字后为具体条件,INNER JOIN和LEFT OUTER JOIN、RIGHT OUTER JOIN关键字必须写在多表之间进行连接
- 左外连接和右外连接都可以查询出存在NULL值的列和没有数据的列
- LEFT OUTER JOIN为左外连接、RIGHT OUTER JOIN为右外连接、OUTER关键字可以省略
3-1. 内连接
- 内连接也无法查询没有值的列和存在NULL值的列
SELECT 表1的列1, 表2的列1 FROM 表1 INNER JOIN 表2 ON 表1的条件=表2的条件;
3-2. 左外连接
- 左边为主表,先写哪一个表就是左表(主表)
SELECT 表1的列1, 表2的列1 FROM 表1 LEFT OUTER JOIN 表2 ON 表1的条件=表2的条件;
3-3. 右外连接
- 右边为主表,后写哪一个表就是右表(主表)
SELECT 表1的列1, 表2的列1 FROM 表1 RIGHT OUTER JOIN 表2 ON 表1的条件=表2的条件;
3-4. 全连接
- 部分其它品牌数据库可以使用FULL JOIN关键字进行全连接查询,但mysql不支持此关键字
- mysql里可以使用UNION和UNION ALL关键字,UNION为合并相同的记录,UNION ALL为不合并相同的记录
(SELECT 表1的列1, 表2的列1 FROM 表1 LEFT OUTER JOIN 表2 ON 表1的条件=表2的条件;)
UNION
(SELECT 表1的列1, 表2的列1 FROM 表1 RIGHT OUTER JOIN 表2 ON 表1的条件=表2的条件;)
练习
- 查询所有的员工和其对应的部门
- emp为表1、dept为表2、uname为员工姓名的列名、dname为部门列名、deptid为部门编号列名、did为员工编号列名
SELECT ename,dname FROM emp,dept WHERE deptid=pid;
sql语句书写顺序概要
- SELECT
- distinct 列、聚合函数(列)
- FROM 左表 右表 ON 联合条件
- WHERE 条件
- GROUP BY 分组查询
- ORDER BY 排序条件
- LIMIT m,n 分页